On Tuesday, June 15th 2021, we picked-up where we left off with the “Common Engineering System at WorkSafeBC“ session, on the April 2020 meetup.

We shared our insight into our ambitious journey to consolidate hundreds of inconsistent continuous delivery pipeline snowflakes into state-of-the-art pipeline-as-code, based on YAML and re-usable templates. Here is our story!
WHY?

Donovan Brown defines DevOps as the “the union of PEOPLE, PROCESS and PRODUCTS to enable the continuous delivery of value to our CUSTOMERS”. The word continuous in Donovan's statement implies that we automate everything automatable, move repetitive tasks to machines, and enable engineering to focus on delighting our customers with features.

In addition, the agents of chaos created guardrails defined by five essential values for the DevOps mindset. One of the values encourages us to innovate and improve beyond repeatable processes by reducing waste and not doing things with no value or purpose.
As alluded to by the checklist we built up during the session, we are not talking about pipelines to carry oil, but an enabler to automate continuous integration and delivery tasks. We embraced the Azure Pipelines years ago and standardized on what we refer to as the unified pipeline guardrail. It helped us build once, deploy the same build artifact to different environments, and streamline our manual approvals.

We were in technology heaven, until our automated weekly pipeline reports unearthed a scary and unnerving reality. Over 3000 pipeline definitions, growing at an alarming rate, and creating a pile of costly technical debt. Autonomy inspired a variety of snowflakes, some of which introduced vulnerabilities, and more recently, a growing number of release rejections due to security review failures.
We also picked up that Microsoft began referring to the user interface based Azure Pipelines as classic and stopped investing in the technology. As the classic and deprecated rot was setting in, we started to experiment with YAML-based Azure Pipelines in two consecutive hackathon events. We did not catch the attention of business and won no prize but embarked on an exciting pipeline journey with ambitious goals: alignment, consistency, simplicity, security, flexibility, and transparency.
Read Part 1: Pipelines - Why bother and what are our nightmares and options? for more details.
WHAT?

We fell in love with the potential of new YAML-based Azure Pipelines, based on a mature and human readable data serialization, originally proposed by Clark Evans in 2001.
YAML is often referred to as “yet another markup language” and “YAML ain’t markup language.
Azure DevOps YAML pipelines are structurally YAML. Microsoft introduced no deviation or snowflake and forked the Azure DevOps pipeline repository to build their GitHub pipelines. Like applying a protective anti-rust coating on our Azure DevOps pipelines and opening exciting coexistence and future migration opportunities.
Our pipeline working group switched their focus on pipeline as code, a term introduced by Jenkins. It is a technique that treats the pipeline configuration as code, placed under version control, packaged in reusable components, and automated deployment and testing. Comparable to infrastructure as code and the golden fleece for our pipeline adventure.
Pipeline as code enables us in many ways:
- All pipeline artifacts are placed in source control repositories, which can be viewed by all our engineers. There are no secrets!
- Tick off one of our goals, transparency, a core ingredient to Agile and Lean development, as well as a healthy DevOps mindset. It fosters TRUST.
- Allow our engineers to contribute to our common engineering system by submitting pipeline changes and innovations through the pull request workflow. We are centralizing, not standardizing, and enable engineers by injecting re-usable templates.
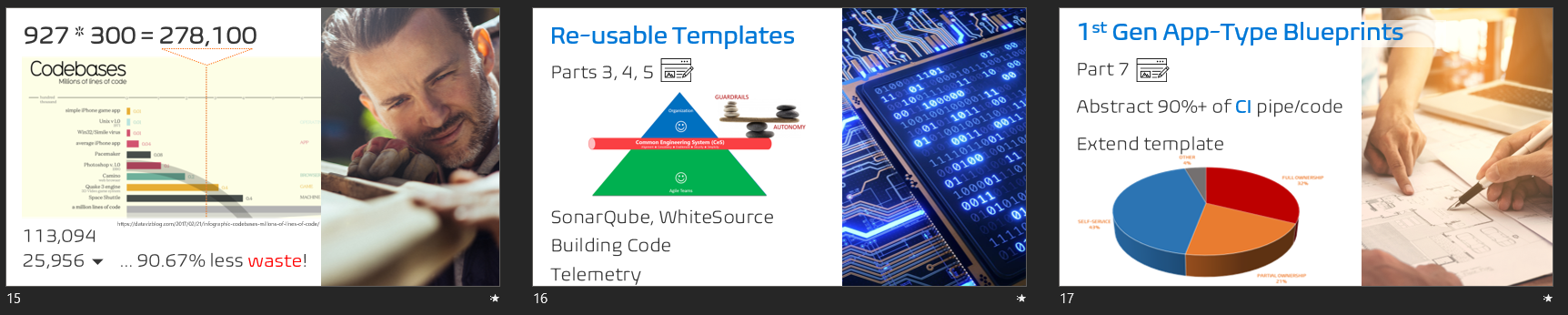
During the hackathons and subsequent proof-of-concepts we highlighted not only the risk of rotting technology, but engineering distractions and focus on waste, instead of value. For example, a typical YAML-based CI pipeline for an Azure Function requires 300 lines of code. With 927 continuous integration build pipelines, this amounts to a mere 278,100 lines of code that engineering need to craft. More than Photoshop 1.0 and just less than the Quake 3 engine. In my humble opinion, a huge pile of WASTE.
Our first-generation generic blueprint-based pipelines reduced this to 113,094 lines of CI code and to 25,956 lines of CI/CD code using our second-generation app-type blueprint-based pipelines. Read parts Part 3: Pipelines - Basic building blocks as templates and sprinkling on telemetry, Part 4: Pipelines - Magic of queue time assembly, Part 5: Pipelines - Blueprints to fuel consistency and enablement, and Part 6: Pipelines - Gotcha! The generic blueprint-based YAML pipeline simplicity of our pipeline series on our technical WorkSafeBC blog for more information.
Templates allow us to define reusable CI and CD tasks, keeping our main pipeline definitions razor focused. They enable us to script and assemble pipelines at “queue” time. And most important, instead of editing hundreds of classic pipelines in a GUI editor, which can be mind numbing and error prone, we edit one template to make a change such changing guardrails. Once the template is saved, the change is automatically injected into all pipelines queued thereafter.
MAGIC!
For details on our 1st generation blueprints, read Part 7: Pipelines - There is more! Simplicity and enablement, courtesy of the app-type blueprint-based YAML pipelines.
As a software developer, do I want to own, for example create and maintain, the pipelines to build and deploy my application?
After more than 36 years of engineering software solutions, my answer is NO. I will be glad to let another team take that responsibility while I focus on creating value for the business by delivering quality software. I just want access to the build pipeline templates and an ability to suggest changes, so that I can learn, innovate, and troubleshoot issues, if any.
The 1st generation app-type blueprints introduced re-usable application type continuous integration blueprints, which typically required me to update 2-3 lines of configuration and I am done with my pipeline.
Some of the fairy dust is the extend template feature in the YAML-based Azure Pipelines. It allows us to verify that a pipeline is based on a known and trusted template. If not, it is automatically rejected by service connections and/or environment checkpoints - at run time, with zero humanoid intervention.
But, you guessed it, there is more.

If you read Part 8: Pipelines - Pipelines - From CI to CD and beyond in one pipeline of pipeline series, on our technical WorkSafeBC blog, you will be amazed with our 2nd generation app-type blueprints, which are in early preview in two of our engineering environments.
The 2nd generation adds the same magic we discussed for continuous integration, to the continuous deployment. Thanks to pipeline as code and the way we have structured our pipelines and template repository, all engineers can review all templates, and submit improvements via a pull request. If the proposed change is within our guardrails the pipeline working group innovates. If not, we collaborate with engineering and DevSecOps, occasionally terminating the pull request with “Kevin said so.” More about that in a minute.
We have not realized our dream for self-service automation yet. However, we have reached a stage where our blueprint-based pipelines are automation enablers, consistent, and simple. Furthermore, our pipeline working group is collaborating with the automation working group to realise our“Hello world in less than 1min”, aka walking skeleton, goal.
Would you prefer working in a manual humanoid driven world, or in an automated humanoid enabled world?
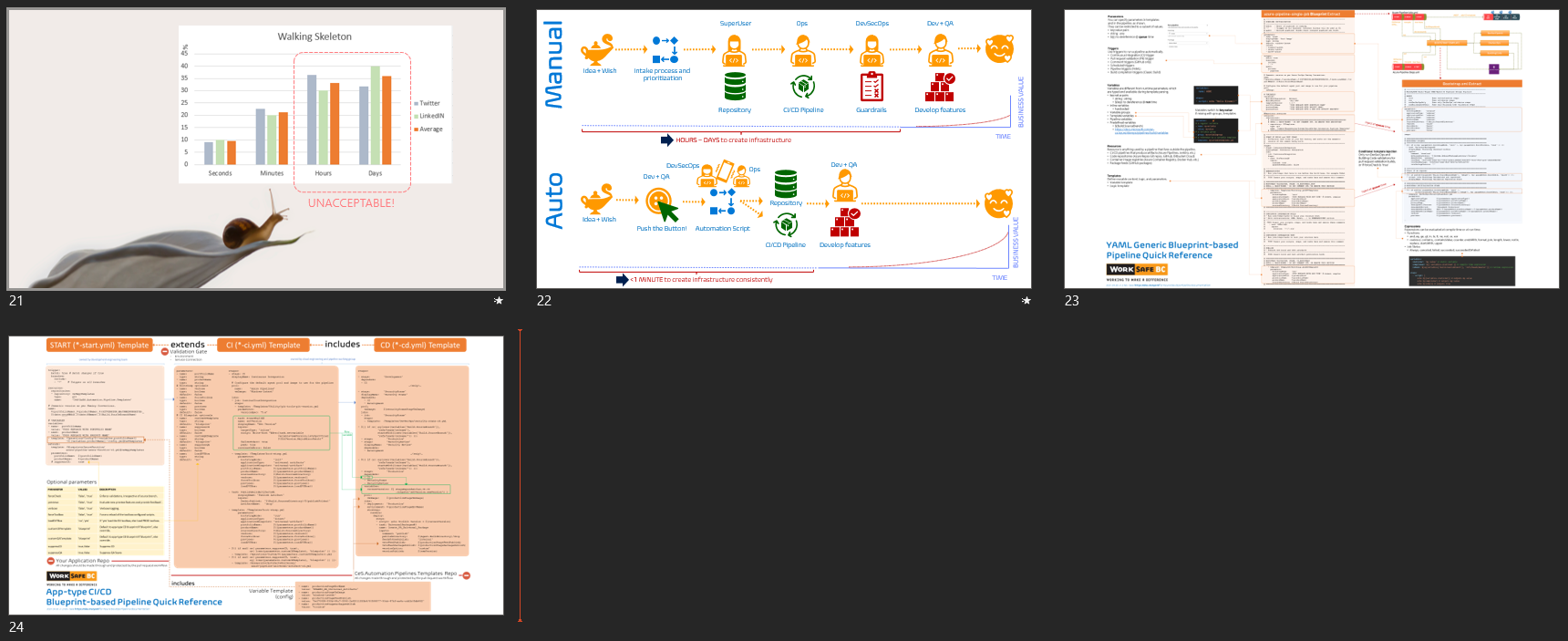
Looking at the quick poll results (slide 21) from Twitter and LinkedIN I am astounded at the percentage of engineers who tolerate hours to days to get a "walking skeleton" created for them. When I combine the two polls, an average of 33% are experiencing hours and another 36% days. That adds up to 69% ... I am gob smacked and shocked! I hope that we can come back to continue this session to share the success stories from our automation working group.
HOW
HOW we managed, and at times battled, to grok the intricacies of YAML, evolve the emerging application-type blueprint-based pipelines, and enable automation was beyond the scope of this session and we deferred the HOW for another day. Instead we shifted our focus to get a view through a software development engineer's and security engineer's lens.
A peek through a Software Development Engineers' Lens

Said delivered a great demo of our 2nd Generation App-type CI/CD blueprint, which we are previewing in two engineering environments. It was such a great demo, that I completely forgot to take screenshots.
Watch the recording on DevOps Vancouver Meetup: June 2021, once it is published, and auto-forward to Said's demo. You will be mesmerized!
We also asked Kevin, why pipelines are so important to security and why he has been smiling from ear to ear, ever since the blueprints emerged from the pipeline working group.
A peek through a Security Engineer's Lens

Time to invite our security lifeline. Kevin answered two of my questions and much more:
- Can you give us an insight into your world and explain why are the pipelines so important to security?
- Could you enlighten us, why you been smiling from ear to ear, ever since the blueprints emerged from the pipeline working group?


What is next?
Hopefully, we will return to the meetup with the automation success stories soon. We will demonstrate that it takes seconds, not minutes, hours to days, to create a new repository, add sample code, 2nd generation app-type blueprint-based CI/CD pipeline, tie everything together, and queue a continuous integration build for the newly created environment.
DOWNLOAD >> devops-meetup-wsbc-pipeline-story deck
DOWNLOAD >> devsecops-pipeline-presentation.pdf

If you have any question or feedback, please ping us on twitter @saidakram007, @604kev, and @wpschaub
Feedback from the peanut gallery
I had a good fortune to attend the DevOps Meetup session that Willy described above. As an innocent bystander, I'd only like to add a couple of observations:
Willy's explanation regarding minimizing waste is spot on. We do not want to spin off hundreds or thousands unique infrastructure solutions. Computing infrastructure is a commodity (i.e. dime-a-dozen) and it is therefore truly wateful to burn precious engineering cycles in re-inventing the wheel, so to speak. Willy and the crew are working hard on commoditizing all aspects of the infrastructure-as-code so that the engineers could sharpen their focus on making changes that are not available elsewhere (i.e. not commoditized on the market).
Willy did, however, point out the fact that innovation is crucial, and that engineers are empowered (and advised) to work on improving the offered commodities. That's the true value stream delivery -- work smarter, not harder.
Finally, the strongest takeaway from the session (for me, at least) was the conclusion that security concerns must become top of the mind for every engineer. Before making any changes to the system, the first thing we should ask ourselves is: "Is this change secure? Is it testable by running automated tests?" Only after we prove it to ourselves and to our coworkers that the change is secure and fully testable, should we continue making the desired change.
Overall, this was a fantastic session; looking forward to part 2! (Alex Bunardzic)