Welcome back to another installment of pipeline wizardry. In part 7 we wrapped up our application-type continuous integration (CI) pipeline. OK, we have nailed the build, but what about the release, aka continuous deployment (CD)?
Why do we care about continuous deployment?
In previous posts we covered the world of Continuous Integration (CI), which builds and validates your latest code in your source control repository. With Continuous Delivery (CD) we deploy the artifact from the CI build to one or more environments.
In the MSDN article, Applying DevOps to a Software Development Project, I emphasised the subtle difference between Continuous Delivery (CD) and Continuous Deployment (CD): "The latter is to a single environment. A small team might only implement Continuous Deployment because each change goes directly to production. Continuous Delivery is moving code through several environments, ultimately ending up in production, which may include automated user interface (UI), load and performance tests and approvals along the way."
Note that both have the dreaded TLA (two|three lettered acronym) CD? ... confusing, right? Oh, how I loathe IT (information technology) acronyms q;-(
Back to Continuous Deployment, which seems important. It deploys new features, bugs, and hot fixes, which we can release to our delighted customers on demand.
The use of "continuous" implies that both the continuous integration and continuous deployment engineering processes embrace the "automate everything automatable" motto!

After being flabbergasted with the innovation, simplicity and enablement, courtesy of the app-type blueprint-based YAML pipelines, I expected a world of frustration and pain to embrace the blueprints within the context of Continuous Deployment.
Here is the final chapter in our blueprint-based pipeline adventure.
Tweaks to the Application-type CI Blueprints
We continue from where we left off with the app-type CI Blueprint Architecture, comprised of the following key elements:
- [ ] Starter template, which configures the continuous integration pipeline.
- [ ] App-type CI template, which extends the starter template and abstracts the continuous integration (CI) process.
- [ ] Example of the app-type blueprint, for reference.
App-Type CI Blueprint Architecture
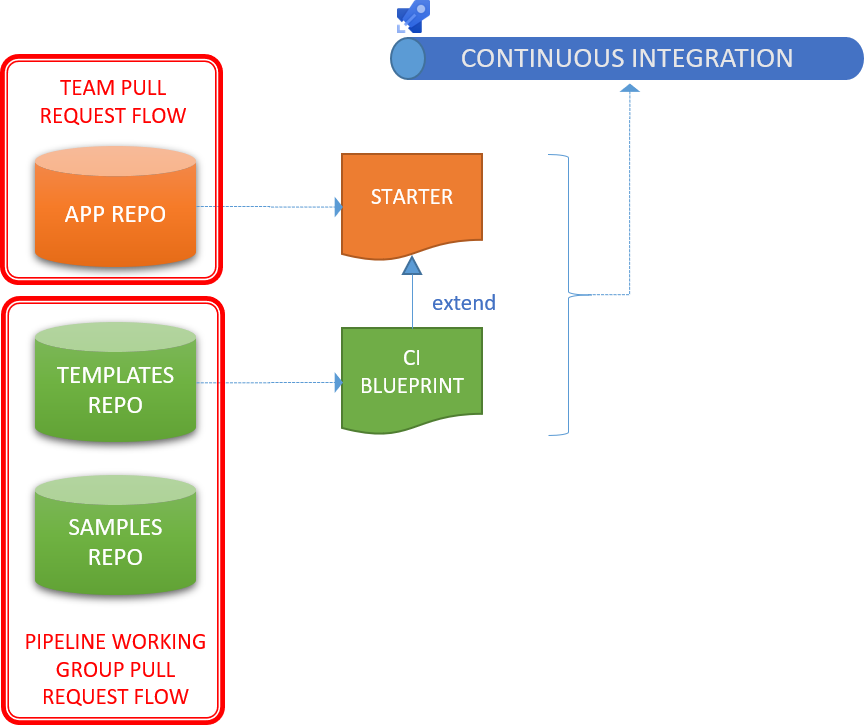
We add two templates to the CI Blueprint Architecture to create our CICD Blueprint Architecture.
- [ ] App-type CD template, which abstracts and includes continuous deployment (CD) process.
- [ ] Variable template, which contains all configuration for the various deployment jobs and environments as key:value pairs.
App-Type CICD Blueprint Architecture
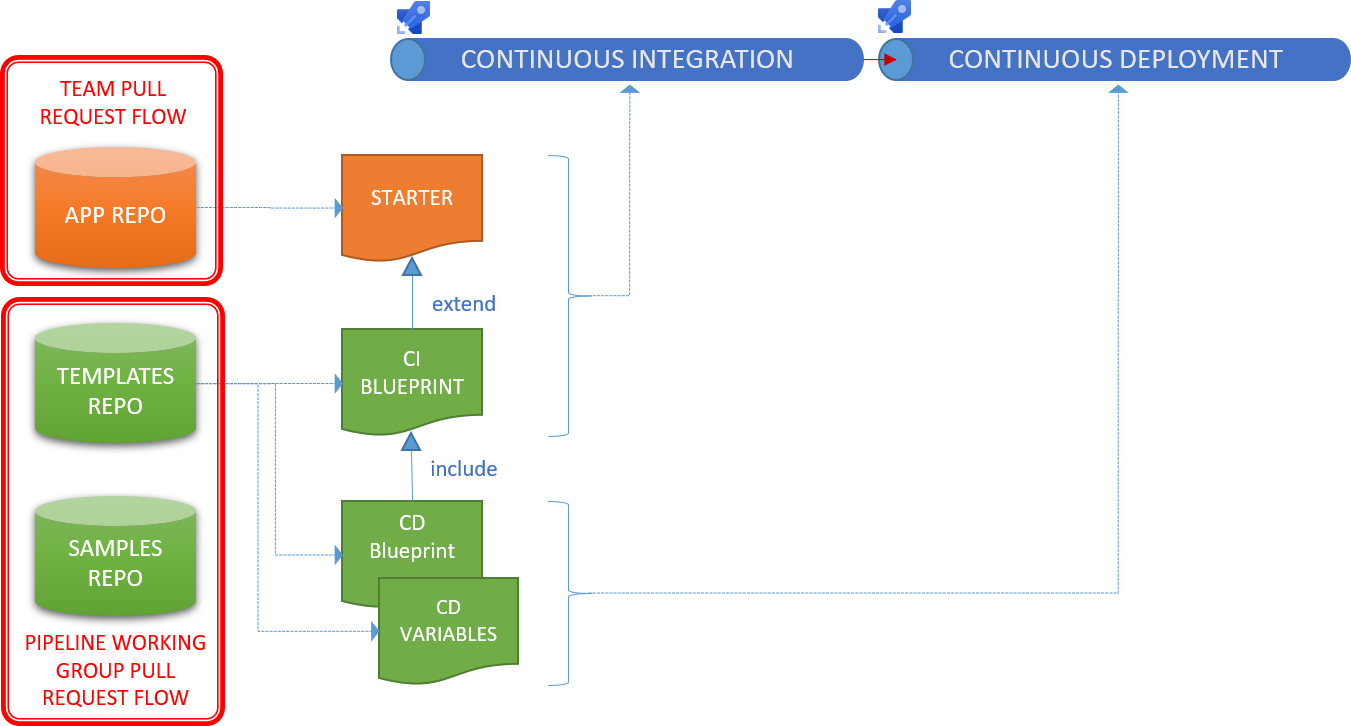
It took us minutes to create a fully functional CI/CD pipeline using the App-Type CI Blueprint. In fact, it is was so painless and quick, that I repeated the exercise to verify the process.
I hope that you have appreciate the simplicity, power, and prospects that the YAML templates and our app-type blueprints are bringing to the party. Now let us explore what we had to change since my engineering colleague Said Akram published Part 7: Pipelines - There is more! Simplicity and enablement, courtesy of the app-type blueprint-based YAML pipelines.
Starter template tweaks
When you include variable groups or variable templates, you need to switch your variable definitions to the sequence syntax. To add the variable template, we changed our Starter template from the simple notation ...
SAMPLE: Variables using simple notation
variables:
portfolioName: 'TODO REPLACE WITH PORTFOLIO NAME'
productName: 'TODO REPLACE WITH PRODUCT NAME'
... to the key:value notation. The variable template name is assembled from the portfolio and program name and pulled from the same repository as the other templates.
SAMPLE: Variables using key:value pair notation and variable template extract
variables:
- name: portfolioName
value: 'TODO
- name: 'TODO REPLACE WITH PORTFOLIO NAME'
value: 'TODO REPLACE WITH PROGRAM NAME'
- template: CD/Config/${{variables.portfolioName}}.${{variables.productName}}.config.yml@CeSTemplates
CI template tweaks
Changes to the CI template were just as humdrum. An optional parameter allows us to override the app-type CD template, with a custom template on exceptional cases.
SAMPLE: CI template extract
parameters:
...
- name: customCDTemplate
type: string
default: 'blueprint'
...
# DEPLOYMENT
- ${{ if ne( parameters.customCDTemplate, 'blueprint' ) }}:
- template: CD/Custom/${{parameters.customCDTemplate}}.yml@CeSTemplates
- ${{ if eq( parameters.customCDTemplate, 'blueprint' ) }}:
- template: CD/Blueprints/<appType>CDTemplate.yml@CeSTemplates
# END OF PIPELINE
We are experimenting and fine tuning our variable and CD templates and therefore it would be overzealous to include them in entirety.
As mentioned, the variable template is a list of key:value pairs to define configuration for the associated deployment jobs and environments.
SAMPLE: Variable template extract
variables:
...
# DEVelopment Stage
- name: developmentStageEnvName
value: 'POC_DEV'
- name: developmentStageVmImage
value: 'ubuntu-latest'
For the CD Blueprint, you should explore deployment jobs and associated strategies. To start, we opted to experiment with the runOnce strategy.
SAMPLE: CD template extract
stages:
# DEVELOPMENT STAGE
- stage: 'Development'
dependsOn:
- ContinuousIntegration
pool:
vmImage: $(developmentStageVmImage)
jobs:
- deployment: 'Development'
environment: $(developmentStageEnvName)
strategy:
runOnce:
preDeploy:
steps:
- script: echo Welcome to PREDEPLOY - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
deploy:
steps:
- script: echo Welcome to DEPLOY - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
routeTraffic:
steps:
- script: echo Welcome to ROUTETAFFIC - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
postRouteTraffic:
steps:
- script: echo Welcome to POSTROUTETRAFFIC - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
on:
failure:
steps:
- script: echo Welcome to FAILURE - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
success:
steps:
- script: echo Welcome to SUCCESS - Development stage running on $(developmentStageVmImage) pool in the $(developmentStageEnvName) environment
OK, the template revisions to include continuous deployment are straightforward. Apart from many upcoming refinements, we now have a functional application-type CICD blueprint-based pipeline.
But, how do they map out at queue time and are our security engineers contempt with the new pipelines?
Mulling over environments and/or service connection approvals
We can define approvals and checks to service connections or environments. The jury is still out whether we will use the one or the other, or both. We opted to start with and validate Environments, which are collections of resources for our typical Development, System Test, Staging, and Production environments.

Environments have the following advantages:
- Deployment history is maintained for each environment.
- Insight into jobs, tasks, and gate results
- Ability to lock-down environments by specifying which users and pipelines can target an environment.
- Environments can be shared across pipelines. For example, we only need one Security Review environment stage, configured once, and mapped to all pipelines.

Unfortunately, approvals and checks can only be configured as pre-environment rules, unlike classic release pipeline where we have pre- and post-stage gates. Unfortunately? It forces us to re-think our deployment approvals, which will bring down the per-stage and total lead times for our pipelines.
See Create and target an environment for more details.
--
Making sure our Security Engineers are happy
With classic Azure Pipelines we use Artifact filters with release triggers to deploy from multiple branches and disable deployment to higher stages, such as production, if the filters are not met. Our security engineers, however, are not fans of Artifact filters, as they can be overridden by users with elevated permissions.
"Though shalt not pass" - Gandalf, Lord of the Rings
In comparison our blueprint-based pipelines use conditional logic, ensures that higher stages are injected, or not, when a pipeline is queued. Remember this quick video from Part 4: Pipelines - Magic of queue time assembly, which reveals the magic.
 [1:52]
[1:52]
As shown below, our pipeline contains the continuous integration, development, system test, and security scan stages when the source branch is anything but release or hotfix*. No-one, even our security engineers and cloud engineers with god-like permissions can override, as the higher stages are simply not available.
So simple, yet so powerful!
Build Artifact triggered by non-release branch

Running the same pipeline where the source branch is either release or hotfix*, the higher security review, staging, and production are included.
Build Artifact triggered by release branch

The actual conditional logic is trivial. Here is an example:
# STAGING STAGE
- ${{ if or( eq(variables['Build.SourceBranch'], 'refs/heads/hotfix'), startsWith(variables['Build.SourceBranch'], 'refs/heads/release')) }}:
- stage: 'Staging'
dependsOn:
- SecurityScans
- SecurityReview
...
Mission accomplished :) Happy ~~wife~~ Security engineers, happy life!
Are our engineers losing control over their pipeline?
Then again, we received harsh feedback from a recent poll, where we asked our engineers and the community if they want full control, partial control, or pipeline as a service. Only 41% of all engineers support the idea of pipeline as a service and some comments made us take a few steps back and re-think our strategy. For example:
- Well, autonomy is important, with centralizing the templates, you are creating impositions (you are imposing workflow, so how they work) in the teams, while you should focus on the outcomes.
- Organizations that think they can cover 80% or even 90% of pipeline use cases always seem to miss the mark. I think folks that feel that this can be pulled off have been working at the same place or same vertical for too long.
- Not all software developers are the same.
- ... and so forth.
Engineers want partial or full control of CICD pipelines

After a lot of soul searching, discussions with software, security, and operation engineers, and considering that we have less than two handful of different system and technology architectures, I said: "Exactly!"
With our application-type blueprints we are pursuing the best of the autonomy and governance world. We are enabling our:
- Software engineers to be razor focused on delivering value to their customers.
- Security engineers to define and inject guardrails into all our pipelines.
- Operations and site reliability engineers to focus on our infrastructure, maintenance, and support.
- Architecture engineers to define a consistent way to deploy each application architecture.
What is the point (value) of allowing software engineers diverse ways of building and deploying an Azure Function? More importantly, why would we want to impose different solutions for the same solution for operations and site reliability engineering to maintain and support?
I am looking forward to a storm of feedback, comments, and discussions. Let us focus on the question "Are our engineers losing control over their pipeline?"
The answer is a bold and blinking NO!
As discussed in this and previous posts, we are storing all our starter, bootstrap, blueprint, and guardrail templates in a common Git repository that anyone can view. There is more. Everyone can submit a pull request with proposed changes, innovations, and bug fixes and thereby update the templates.
Build Artifact triggered by non-release branch
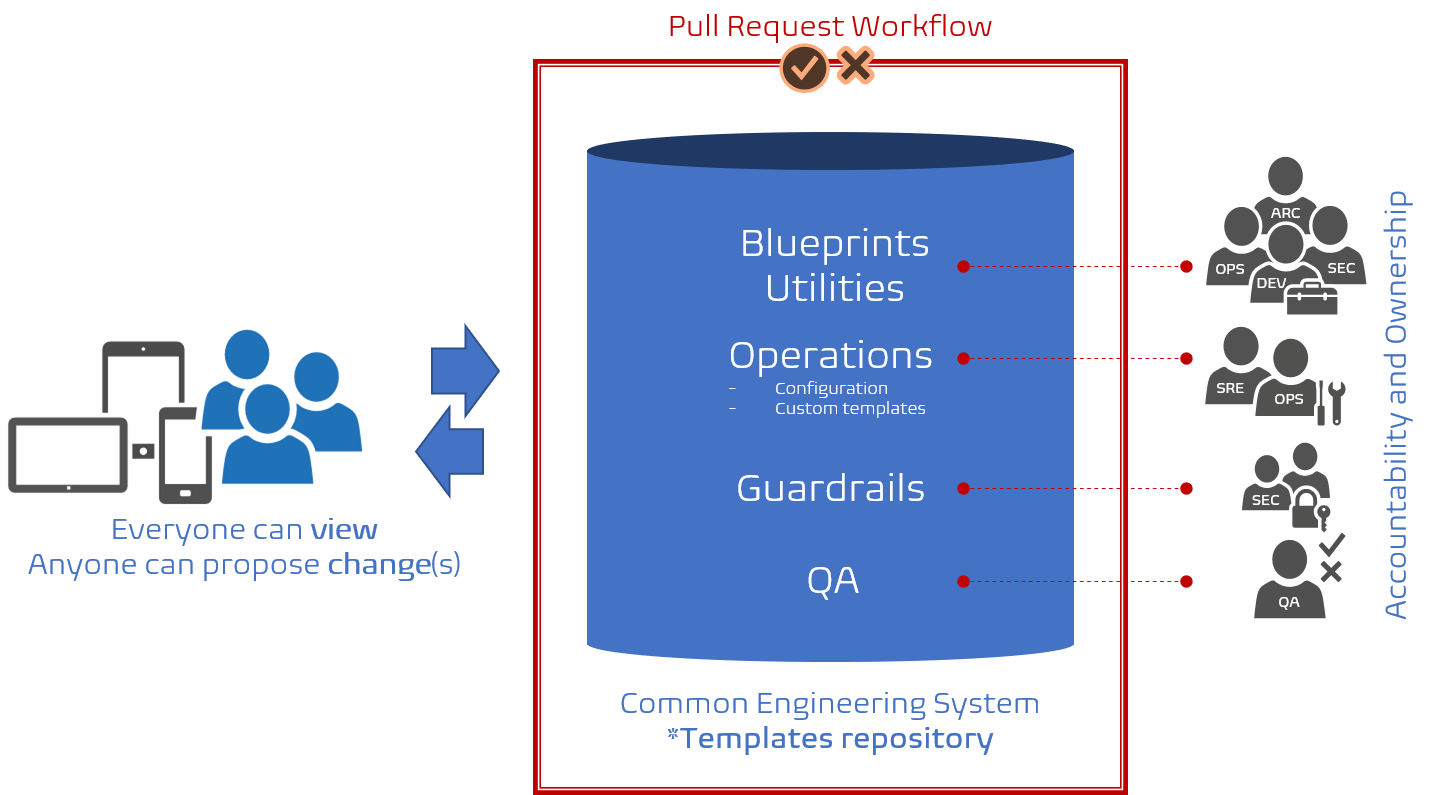
That said, not all ideas and proposals neatly packaged in a pull request will be accepted by the team(s) accountable for the impacted templates. We have a responsibility to maintain and uphold our common engineering system manifestos and guardrails. If you wander outside the guardrails and are unwilling to discuss the WHAT, WHY. and HOW your pull request will be rejected. Why? 'cause our security engineer Kevin, said so! Security is not only pivotal to our healthy DevOps mindset, it is non-negotiable.
Build Artifact triggered by non-release branch
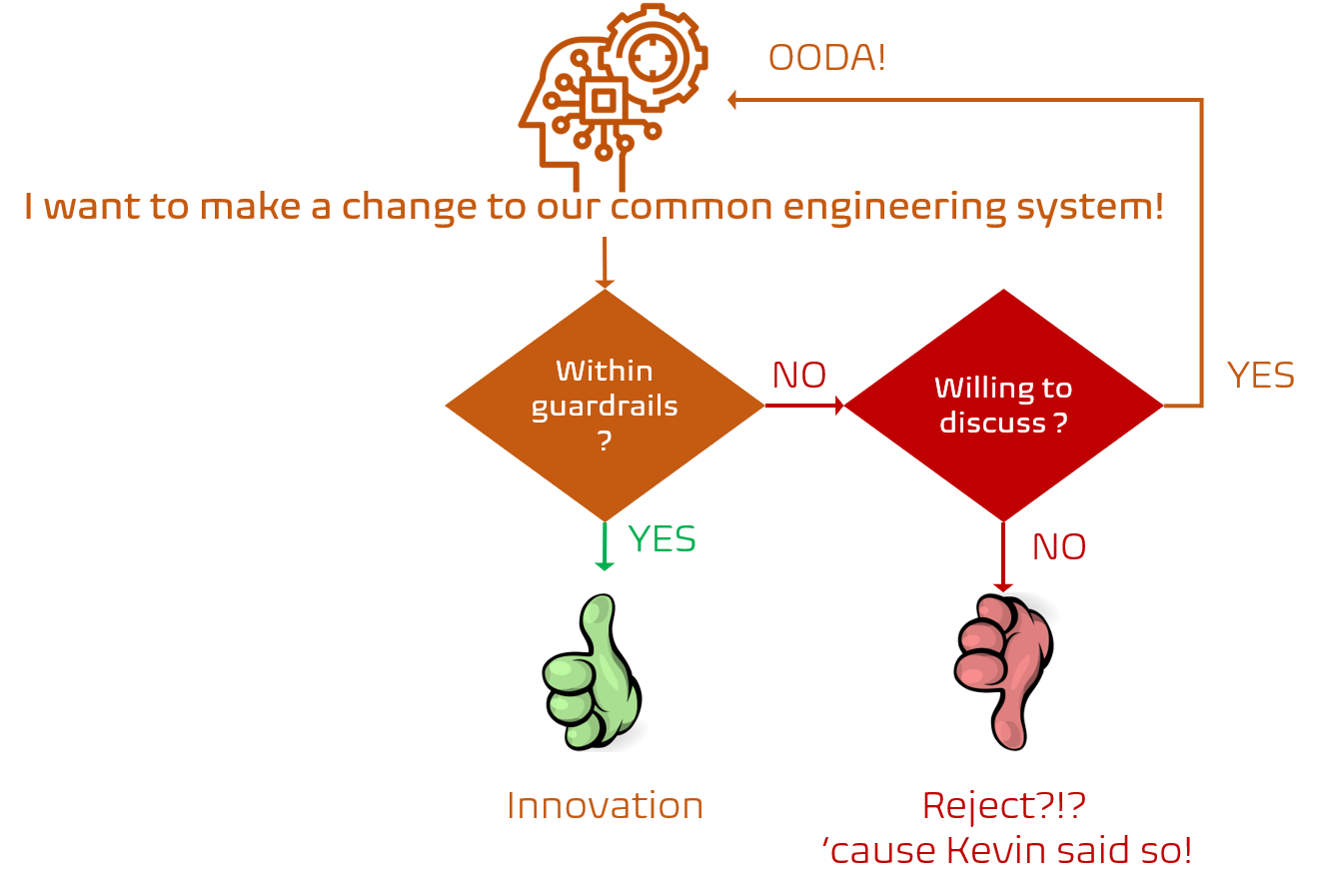
An in-house ~~joke~~ reality, sorry!
What is next?
We are working on rolling our first two CI/CD blueprints for Azure Artifact and Azure Function pipelines, we will run ample workshops and awareness sessions to introduce all stakeholders to the new age of pipelines, we will lean on the observe-orient-decide-act (OODA) loop, by John Boyd, to fine-tune both blueprints and supporting infrastructure, before we embrace our other solution architectures.
We may share our experience and learnings in more posts in this series if there is an interest or jump straight to the last planned post of this series "Self-service automation - A dream turns into reality".
The consistent, secure, and simple blueprint-print based pipelines enable our automation goal!
If you have any questions, feedback, or would like to start a discussion on anything we have discussed in this series, please ping me on twitter or linkedin.
Series Bread Crumbs | Part 1, TOC | Part 2 | Part 3 | Part 4 | Part 5 | Part 6 | Part 7 | Part 8 | Part 9 | Part 10 | Part 11 |