We have all been there. Minutes after releasing a new application feature, our support phone lines are flooded with calls from frustrated customers. Deploying new features to production can be risky business, especially when our goal is to always have delighted customers.
What if we could progressively test and validate new features in production, with a small and focused group of early adopters? Would it not be phenomenal to fine-tune the customer’s experience of our product in production, or better, let our customer determine how and when to experience new features? Have we not wished we could revert our release with a flip of a switch as soon as we detect smoke?

We believe in continuous learning. Last week we hosted an Azure Pipeline workshop, attracting 74 humanoids from engineering, and this week Christine Ozeroff, Anthony Foli, and I hosted an interactive lunch & learn, to share experiences with Feature Flags, share the pros and cons, and unintentional misuse of feature flags.
This is a crisp summary of the session.
Core theme
WHY
With feature flags we have an option to continuously conduct experiments, progressively expose, test, enable and disable features, and pivot on the feedback … all in production. More importantly, we can separate deployments from releases, and release on demand.
We have one of many ingredients that support a healthy DevOps mindset.
"DevOps is the union of PEOPLE, PROCESS and PRODUCTS to enable the continuous delivery of value to our CUSTOMERS.” - Donovan Brown
In other words, Feature flags are one option to decouple feature deployment from release, and fine-tune feature exposure, down to the individual user.
When we look at Microsoft Edge and Azure DevOps, we notice another invaluable strategy. Preview features are deployed continuously and hidden by default. Users, like you and I, can toggle the preview feature flags ourselves and manage our experience of the products. It empowers me, as the end-user, and delivers invaluable metrics to the engineering team. For example, which features are popular
WHAT
For Product Owners feature flags are an ON OFF switch. For Developers they are an IF ELSE programming construct.
WHAT are feature flags?
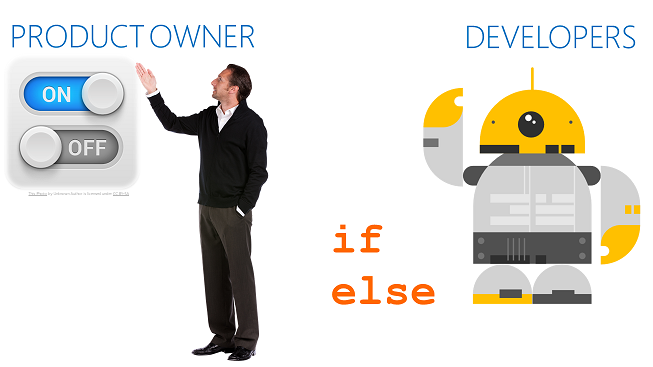
HOW
I urge everyone to pause, before jumping into the deep end and introducing feature flags in your solution. You need an understanding of feature flags, governance around usage, maintenance, and ownership.
WHY? Because progressive exposure (aka feature flags) comes at a cost!
By adding flags, we are adding technical debt to our code, increasing code and test paths as shown. We must steward a feature code path for the ON state and another for the OFF state, and a unit test for both.
Make sure you understand the implications of flipping a feature flag, so that you can avoid the scars I have from previous feature flag implementations.
- A Rough Patch | Brian Harry's Blog
- How we checked and fixed the 503 error and Performance issue in our Azure Function
Protect your infrastructure from such unexpected processing surges, by using retry patterns, throttling patterns, and circuit breakers. See 3 ways to handle transient faults for DevOps for more information.
OUR FEATURE FLAG MANIFESTO
- All feature flags must support the kill switch.
- Feature Flags are managed by Business, Security, & Quality Assurance … not development.
- Feature Flags are used to protect only production ready code.
- We favour software as a service over custom code.
To summarise the VALUE of using feature flags …
- You can ship code when you are ready.
- You can test your code in production.
- In case of an emergency, you can disable a feature.
- You can control your user’s experience or empower users to control their experience.
- And most importantly, you can experiment, learn, and adapt in production.
Before you commit to feature flags, please ask yourself at least FIVE times, “WHY do we need feature flags?”
Also, ensure you have an owner for your feature flag solution and associated feature flag configuration. Especially if it is a custom solution!
Remember, feature flags are not free!
Q&A

Here are a few of the questions we got during the lunch & learn, shared "as-is" in italic. Plus, the answer and/or my personal thoughts.
| QUESTION | ANSWER / THOUGHT(S) |
|---|---|
| Feature flags should be short-lived? | Once a feature is released, the associated feature flag should be deprecated and removed from the system. Similarly, once we have completed an experiment and the associated hypothesis has been proven or disproven, the associated feature flag should be retired. I recommend the following: 1. If you do not need feature flags, do not use them! 2. If you use them, ensure they are short-lived! 3. Remove all traces of the feature flags from codebase as soon as possible! |
| What is the development overhead for building feature flags? If i want to compare with the release overhead ..? I do understand Feature flags offer more flexibility. But the governance is very important. | Adding feature flags and toggling feature flags is trivial. Managing feature flags and understanding dependencies is complex, yet pivotal to a healthy solution. It is difficult to quantify the overhead without more context, other than confirming that the overhead is a lot higher and complex, when building your own custom solution. You should not just ask what the overhead is when developing or using feature flag, but also what the overhead is when we release without feature flags to manage the blast radius of new features. |
| Should specific feature flags be deprecated later down the road if they are a permanent feature? | Feature Flags that represent a short- or long-term feature, should be deprecated as soon as possible. Feature Flags should not create a long-term bond with the feature(s) they represent. The longer you allow feature flags to camp in your code, the less likely it will be that engineering can remove them without risk, raising the likelihood that they will remain permanently, compounding your technical debt. |
| So sounds like we would need to understand the feature flag configuration for any prod incidents, in case it was a factor in the incident? And then reproduce this config in test environments if we need to reproduce the problem for troubleshooting? | This is part of the challenge of using feature flags. We need to know the exact state of all feature flags during an incident. It is vital evidence for a speedy remediation and root cause analysis during the infamous 2AM call we mention a couple of times in the Navigating DevOps through Waterfalls journey. |
| Could you give a brief example of how a circuit breaker would function if the need arose - ie. things go wrong after a FF switch is flipped? | As discussed in 3 ways to handle transient faults for DevOps the hypothesis of the circuit breaker pattern is that the failed service call is likely to succeed if (and only if) it is automatically retried after a significant delay. If we flip a feature flag and our backend services are experience unexpected load, for example Active Directory is inundated with authentication requests, the circuit breaker can break the circuit (network connection), shield, and allow the backend services to recover. |
| I think the worst case scenario is if a particular FF config creates a non-trivial data corruption issue which isn’t detected immediately? | Any data corruption is serious. If the act of flipping a feature flag results in data corruption, the kill switch is unlikely to bring any relief. Yes, this is a nightmare scenario, but not limited to feature flags. |
| I am assuming no code should be sunset to the SRE group with any feature flags in it? | Feature Flags should be short-term, focused on preview features. They are not relevant when a solution enters sustainment, maintenance, or sunset mode. In my opinion, the site reliability engineers (SRE) should not accepts a solution that harbours technical debt and stale feature flag logic. The only exception are long-lived operations and security feature flags, but only as an exception! |
| Why do you favour a SaaS solution? | In 2005 I, and many other Microsoft MVPs, had immense fun installing the first versions of Team Foundation Server. It was a painstaking and mind-boggling experience, a drain on engineering resources, and an unrecoverable expense ... but it was fun, for a while. Yes, we had to understand every nut and bolt of the solution and quickly became TFS experts, which resulted in a few of us joining Microsoft. A win for TFS, but a loss for the engineering teams we left behind. Then came Azure DevOps, formerly known as VSO and VSTS, which opened our eyes to the value of Software as a Service (SaaS). No more installations, no more maintenance of hardware, no more patching, and automatic update of features every 3-weeks, The above-mentioned experience convinced me of the value of SaaS solutions. In the context of feature flags, it means we do not have to invest precious development and operational resources to build and maintain a solution that will grow with us - basic feature flag management, A/B testing, stale and dependency flag detection and management, metrics, reliability, scalability, ... the list goes on. |
What do you think?
Session presentation thumbnails
DOWNLOAD >> PDF

Reference Information
- A Rough Patch | Brian Harry's Blog
- Deploying new releases: Feature flags or rings?
- How we checked and fixed the 503 error and Performance issue in our Azure Function
- 3 ways to handle transient faults for DevOps
- Why hypothesis-driven development is key to DevOps
- What's the cost of feature flags?
- Summary of my publications