For the past three program increments, which amounts to a staggering 30 iterations, or 300 days, we have been working on our quest to convert our legacy classic pipelines to YAML-based pipelines, as outlined in our Pipelines - Why bother and what are our nightmares and options series. More importantly, we have been working in parallel to elaborate on the value to our stakeholders.
A tough challenge, because there is no visual value in continuous integration and deployment pipelines to business, our delighted end-users, or our engineers who want full control of our common engineering system.
A recent awareness and prioritisation push by our Release Train Engineers have raised a few interesting questions. This post attempts to give our critics some answers and scratch the surface of the possibilities and values of our new blueprint-based pipelines.
Pipelines as code ... what?
Let us start with infrastructure as code (IaC), which manages and provisions computer data centers through machine- and human-readable configuration files. Instead of humanoids manually clicking and tweaking knobs and dials in a graphical user interface, machines read and process the code. There is no apocalyptic vision of Skynet, only the option of automation and consistent deployment of our infrastructure.
If you view continuous integration and deployment pipelines as infrastructure, we could stop here. However, Jenkins introduced the term "pipelines as code", which is more fitting.
It is a technique that treats the configuration of our continuous integration and deployment pipelines as code, placed under version control, packaged in reusable components, and automated deployment and testing ... like IaC.
The YAML-based pipelines in Azure Pipelines, opened the golden fleece, not pandoras box, for our pipelines as code adventure.
Benefit #1 - Transparency
Software engineering is complex and involves stakeholders from all walks of life. Transparency is considered one of the core ingredients to Agile and Lean development, as well as a healthy DevOps mindset.
Transparency avoids assumptions, secrets, and conspiracies - instead, it fosters trust.
With Azure Pipelines all pipeline artifacts are placed in source control repositories that can be viewed by all our engineers - there are no secrets!
We enable our engineers to explore what is abstracted under the covers, continuously learn, give candid feedback, and trust our common engineering system.
Benefit #2 - Everyone can contribute
The Azure Repos, which we used to store our pipeline code, allow us to set a wide range of branch policies to protect our master (trunk) branch that always reflects a production-ready state. One of the policies enforces the use of Pull Requests, which allows our common engineering team to review and give actionable and constructive feedback to all proposed pipeline code changes.
More importantly, we enable our engineers to contribute to our common engineering system by submitting pipeline changes and innovations through the pull request workflow. All without the need for elevated privileges or specialized roles, such as Super Users, which complicate the administration of our classic pipeline infrastructure and security.
Benefit #3 - Automation
When you do something twice, trice, or more times, you should invest in automation. Machines are much better with repetitive operations than we are and empower us to focus on other, more valuable, services.
The explosive growth of software and our goals for consistency, security, simplicity, and enablement have given rise to continuous delivery pipelines that build and deploy solutions in a standard way.
Our common engineering system is using YAML templates to abstract away implementation details and support our engineering practices. They inject underlying tasks to run security scans, validate our building code, and keep an eye on any binary construct moving beyond our guardrails (more appealing term for governance).
We enable our engineers by injecting re-usable templates when they queue their Azure Pipelines and sprinkling the concept of shift-left automatically and consistently.
As a (intentional) side-effect the pipelines as code also enables our long-term vision for self-service automation. Like a self-service kiosk, we will be able to direct our engineers to a self-service portal that displays a menu of services and facilitates actions to deploy the services in an automated, consistent, and rapid manner.
We will enable our engineers to deploy pipelines and associated infrastructure on their own terms.
Benefit #4 - Focus engineering on business code
Lastly, the most controversial and debated benefit. As software engineers we have an inquisitive mind and an urge to tinker with everything under the bonnet. It feeds purpose, mastery, and autonomy as discussed by Daniel Pink, but it also distracts our razor focus to continuously deliver value to our delighted end-users.
I am also a software engineer at heart and have often found myself spinning off into underlying and unrelated code bases. It is like doing a search on the internet, looking for a specific piece of information, and eventually stepping back from dozens of browser tabs ... "what was I looking for?!?" Interesting, educational, but minimal value to getting the job done and an unfortunate waste of productive time.
Instead, let me try using this clean visualization by Information Is Beautiful, and the latest number of our production pipelines to make my point.
Extract from our weekly Azure Pipelines report: 927 production CI/Build pipelines
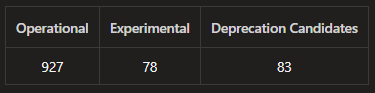
To define a pipeline to build, test, and scan an Azure Function requires roughly 300 lines of pipeline code. The 927 production pipelines are a mix of simpler, but also more complex pipelines, adding up to an astounding 927 * 300 = 278,100 lines of pipeline code.
- If engineers embrace our first-generation generic blueprints, as discussed in Part 5: Pipelines - Blueprints to fuel consistency and enablement and Part 6: Pipelines - Gotcha! The generic blueprint-based YAML pipeline simplicity, the lines of pipeline code are reduced to 122 for an Azure Function pipeline. 927 * 122 = 113,094 lines of pipeline code. A lot less, but still a lot of code.
- If engineers embrace our second-generation app-type blueprints, which Said] will discuss in the upcoming Part 7 shortly, the lines of code are reduced to a mere 28 lines of code. 927 * 28 = 25,956 lines of pipeline code.
Extract from Infographic: How Many Lines Of Code Is Your Favorite App?
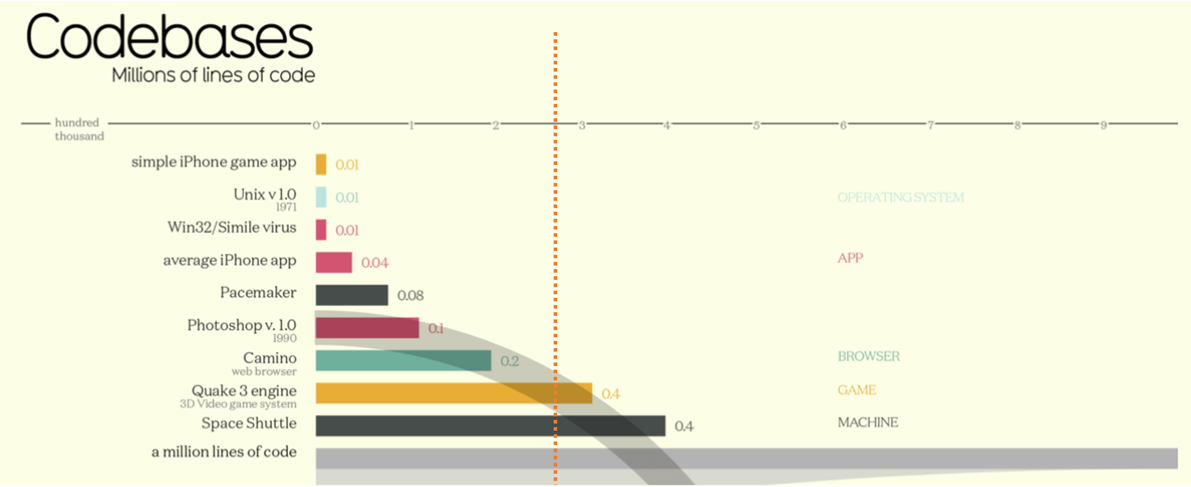
The difference is an astounding 927 * 272 = 252,144 lines of pipeline code, which could be invested in delivering user-value or solutions such as Photoshop v1.0. We have barely scratched the surface of our continuous deployment (CD) pipelines, which is a topic for another day and a few posts; one of my goals is to increase the 28 lines of pipeline code owner by the engineering team by no more than a handful to add CD to our app-type blueprint-based pipelines.
We enable our engineers to be razor-focused on their solution and avoid investing their precious time in wasteful pipeline code.
Wrap-up
You can continue to build your own pipelines, tinker with knobs, dials, configurations, and products, and remember to innovate all pipelines continuously - do-it-yourself (DIY).
Alternatively, you can focus on your business code and let the pipeline engineers focus on your pipelines - pipelines-as-a-service. The choice is yours.