I come from the old school software engineering (started my first programming job back in 1990). Thirty years ago, we were building software the same way we always build high rise buildings. We first obtain the fully fleshed budget and the permission to build. We then wait on the blueprints (requirements) to be signed, sealed and delivered, and then start our ‘brick laying’ work. When we finish building, we ask building inspectors to perform due diligence and confirm if the building is suitable to be put on the market.
Only after all the above activities get successfully completed do we open up our brand new building. We now let people move in.
In the world of software engineering, the equivalent of moving in would be the event of deploying our app to production. Naturally, the grand opening can happen only once, after which we move into the ‘keeping the lights on’ phase (i.e. maintenance).
We call this development model “waterfall” (or, “Big Plan Upfront”).
Current situation
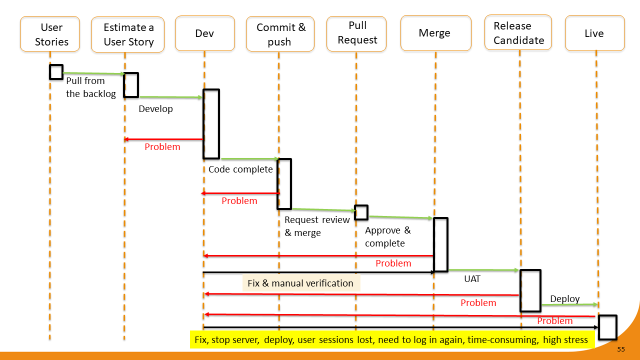
I’ve tried to plot the workflow that may come close to how we are dealing with the deployment workflow today. We start by pulling a story from our backlog. We estimate the story, schedule it for development, and then develop (implement) it. Once we’re ‘code complete’ we commit the code and push it. We then open a PR and if there are issues/problems, the PR gets rejected and the task of fixing the issue goes back to development.
Eventually, when the PR gets approved and the branch merged, if there are no issues the merged code (release candidate) goes into UAT. If there are no problems in UAT, release candidate gets deployed to production.
The real headaches occur when we encounter problems in UAT or in production. These problems must be handled manually (with tedious manual verifications), and the fix to the problem is always very disruptive. To apply the fix, we must stop the server(s) in order to deploy the code. That event destroys all users’ sessions; all user data gets irrevocably lost at that moment. After fixing and re-deploying, we force users to sign in again and start all over, and in general the team goes through a very stressful, even traumatic episode.
Why high levels of stress?
Regardless of the circumstances, it always feels terrible to kick users out of the app while they are in the middle of doing important processing. For that reason, we always prefer to schedule deployments for afterhours. However, that’s often times out of the question because the bug is causing terrible damage to production data and needs to be fixed right away.
Even if we can afford to wait for the afterhours deployment, it is still stressful because we need to schedule for overtime operations staff to work long hours.
What is causing this stressful situation?
The reason we find ourselves in an unenviable position of having to fix the defects by harming the end user experience lies in the waterfall model. Unlike the engineering workflow that manages the building of physical objects (such as a high rise building), software is not well suited for the waterfall approach. When building physical objects, it is intuitively obvious that there must be an orderly sequence of events (i.e. impossible to work on building a roof of the house if the foundation and the walls are not finished). When developing software, those concerns are not a constraint.
Still, the classical engineering mentality tends to get carried over to software engineering. Same as we cannot deliver a partially completed foundation and then deliver partially completed walls etc., the mindset that gets carried over to software engineering insists that all the constituent parts of the solution must be fully fleshed out. That means that rework is not allowed – rework is extremely risky.
In the world of software development, it is actually advisable to focus on partial delivery. Partial delivery implies rework (if something is partial, that means we need to work some more on it).
The waterfall workflow denies rework, and is therefore very disturbed if, after delivering a fully fleshed product, something turns out to be defective. This is due to the fact that in the world of waterfall workflow, failure is not an option. Everything must be delivered fully completed on the first try, because there won’t be any second chance (i.e. second chance was not factored in the budget). Therefore, when something malfunctions, all hell breaks loose. It wasn’t part of the original plan!
How to remove stress from deployment?
In order to minimize and even remove the stress, we must modify the deployment workflow. We must move away from the waterfall model, and into a full blown rework model (where second chances are baked in from the get go).
Let’s examine an aspirational deployment workflow (something I sketched while wearing my optimistic hat):
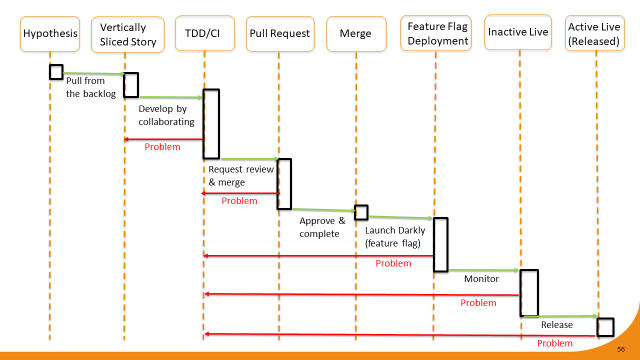
The process starts from the hypothesis (supplied by the business in the form of a user story). We pull one high priority story from the backlog and slice it vertically. We then work on implementing the vertical slice by doing full blown CI/TDD. If we encounter any problems we go back to the user story and refine it. We do all that work by making sure we perform very frequent commits.
When done, we push the changed code to the remote repo and open a PR. If there is a problem with our PR (problem detected by automated tests and linters), it’s back to the drawing board. Eventually our PR gets approved and merged. The merge event signals to the team that absolutely all quality checks have been cleared; our code is good to go.
Next step is to automatically deploy the code to production. Gasp! No, it’s not a typo – we should be free, at any time, to deploy fully tested code to production. However, just because the code is deployed doesn’t automatically mean it is available to end users. We always hide the changes from the users behind feature flags.
Now that our newly minted code is in production, we engage in monitoring its behaviour. We do it by optimizing system observability (collecting and logging telemetry). The production logs should give us sufficient transparency to know whether the code is a solid release candidate or not.
If we discover the problem in production (luckily, no skin off anyone’s nose thanks to feature flags), we open a ticket/spec to go back to development. Write more tests, write more imposters, fix the problem and push the fix through the automated gatekeepers.
Eventually, once the problem is resolved, we release to production. And if despite all precautions we still encounter issues in production, we quickly repeat the automated workflow.
And because all the fixes to the production bugs are going in via feature flags, there is no need to stop and restart the servers. Also, no user session data gets lost; users merely get rerouted to the new code by flipping the feature flags.
Why are frequent deployments so beneficial?
Finally, let’s discuss the merits of frequent deployments. Once we remove the stress factor from the deployment process, we should freely engage in deploying as often as possible.
Why would we want to do that? Frequent deployments teach us invaluable lessons about our market, about our system, about our features. We cannot know whether our changes make sense or not unless we put them out in the field. No focus group can give us accurate prediction on how will a change to the system behave once it goes live.
As the saying goes, the proof is in the pudding.