"Clearly yesterday was a bad day" is a quote by Brian Harry in his Bad Day blog post. I vividly remember that day as I had the honour of working for Brian at the time and learning a ton from him about the value of transparency, not getting discouraged by hindsight, and always being laser focused on our end-users. Our day was nowhere as bad as Brian's, but worth sharing.
In an operational environment with 2500 classic Azure Pipelines and more than a dozen engineers manually updating the pre- and post-approval gates we began to struggle with snowflakes, guardrail breaches, and failed security audits. We configured the pre-and post-approval gates in CSV files and stored them in version control – our config-as-code (c-a-c) era was born. The CSV files and associated automation using the Azure DevOps REST API, allows us to consistently re-apply the last known good configuration for thousands of classic Azure Pipelines in minutes on a weekly basis.
Outcome: Consistency, standardization, security, and time-savings!
Let us have a peak at one of our demo c-a-c files to understand the automation process.
Our configuration-as-code (c-a-c)
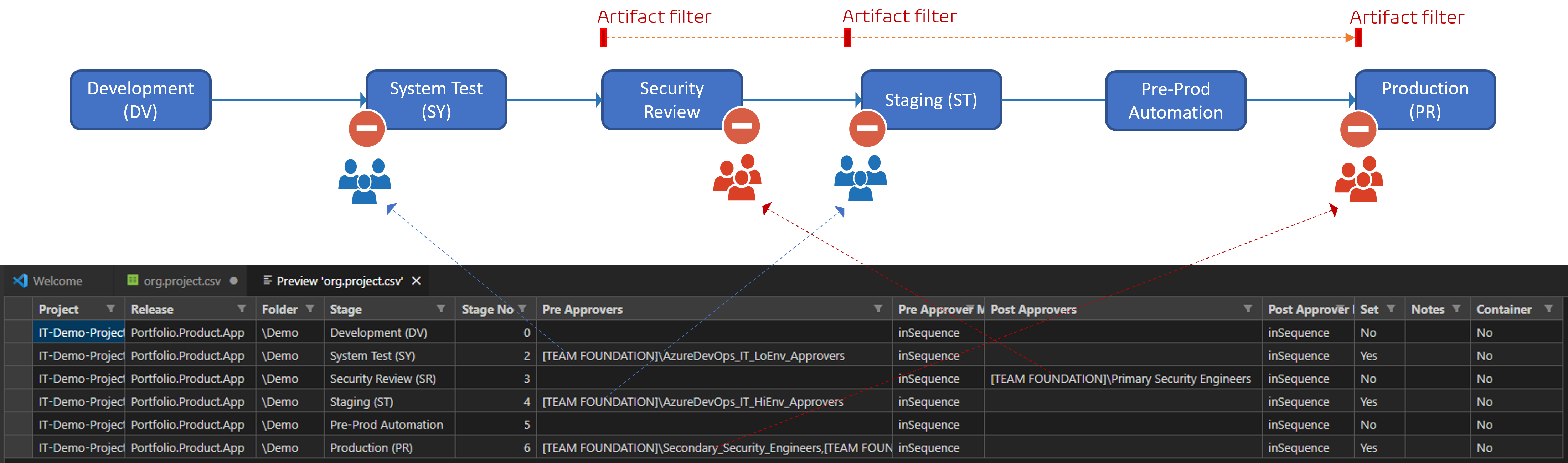
At the top is a typical Azure Pipeline, delivering artifacts to a number of stage environments, with four humanoid gates.
At the bottom is a demo c-a-c CSV file, with one row per stage. Each row defines the pre approver(s), the post-approver(s), and the approval method. When our c-a-c automation runs, it restores the Azure Pipeline pre- and post-approvals to the last known and desired configuration if the Set value is Yes. In other words, if you fiddle with the approvals manually, the automation will overwrite your changes when it runs.
Although the actual REST API logic is not trivial, our c-a-c concept is.
Meltdown timeline
Our bad day actually started on March 2nd at high-noon, when my colleague Daniel ran the latest c-a-c file I fine-tuned for hours. Fortunately, I opted against a big-bang c-a-c reset and only had about 15% of the 2,500 Azure Pipelines and their stages configured with Set=Yes. The automation ran like a dream.
At around 15:00 our delivery teams reported that their pipelines were failing, unable to connect to an agent. At first, we all suspected our automation, because the Azure DevOps Status was showing an Everything is looking good status.

Eventually after a barrage of tweets, Teams chats, and raising Microsoft Support tickets the Azure DevOps Status switched to an unhealthy status due to the Pipeline error: Failure in sending the provision message incident. Little did we know that this incident actually reduced the blast radius of our bad day, as most teams opted for another day by the time the Azure Agents were back to a healthy state.
2AM CALL @ high noon
Just before high-noon we were getting pulled into all hands-on deck, also known as the infamous 2AM-call collaboration sessions. One of our Azure Pipelines had deployed all the way to production, skipping our Staging (ST) and Production (PR) pre-approval gates. Bypassing change control is a severe issue. Luckily our operational support engineers delivered their usual exceptional operational support and reverted the incorrect production deployment within minutes to minimize negative end-user impact.

In parallel we started the brainstorming and root-cause analysis of our Azure Pipelines.
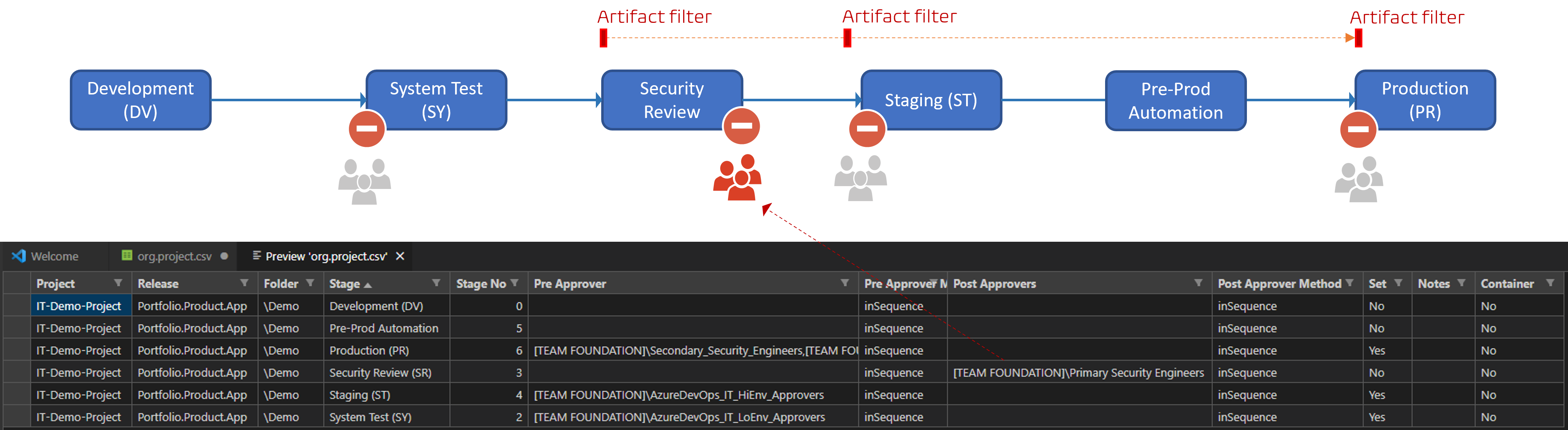
We determined that the automation run, from the previous day, had purged, not set, the pre-approver(s) for all processed pipelines. In other words, the only gate between production and the delivery teams was the Security Review post-approver.
Core Issue
As all software glitches, the root cause was a trivial typo. Note the missing s in the Pre Approver column header.

As a result, the automation did exactly what my configuration file instructed it to do.
- System Test (SY), Staging (SR), and Production (PR) Stage were updated as
Set=Yes. - Pre-approvers were purged as the value for
Pre-Approverswasnull.
Another quote from Brian's post comes to mind here: "The hard thing about this is that anything can go wrong and it’s only obvious in hindsight what you should have been protecting against".
Remediate & Learn
Our focus was, as expected, to restore the health of our Azure Pipelines. Fortunately, only a small subset of Azure Pipelines was affected, thanks to Microsoft outage and our close collaboration with our DevSecOps team.
- Pipelines not triggered by a change to the
releasebranch, were stopped by our artifact filters. - Pipelines that made it through to the Security Review stage, where stopped cold by our security engineers.
In parallel we fixed the c-a-c header and triggered the automation to undo the damage. We also took the opportunity to add pre-automation validation to reduce the likelihood of a recurrence.
And, most importantly, we shared the status of the incident, analysis, root cause, and remediation transparently.
A huge THANK YOU to our vigilant delivery team, security engineers, operations engineers, and my team for keeping cool and focused throughout the turbulent Friday.
Only one pipeline, the one that triggered the incident, made it through to production. It could have been a lot worse!